


If, for whatever reason, you can not reduce the token size of your voice agent prompt but still want to reduce its latency, experiment with a different TTS engine.
Consider the following voice agent:
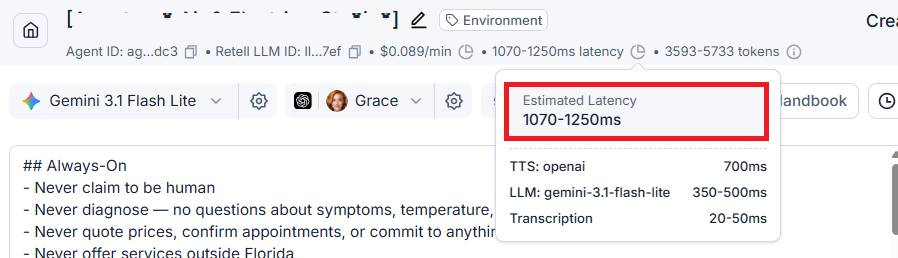
Let's call this agent ‘Agent A’.
The estimated latency of ‘Agent A’ is 1070-1250ms.
It uses the ‘Gemini 3.1 Flash Lite’ model, its token size is 3593-5733 tokens, and it cost $0.089/min.